Scrapy 架构概览
scrapy的架构和它各组件之间是如何互动的?
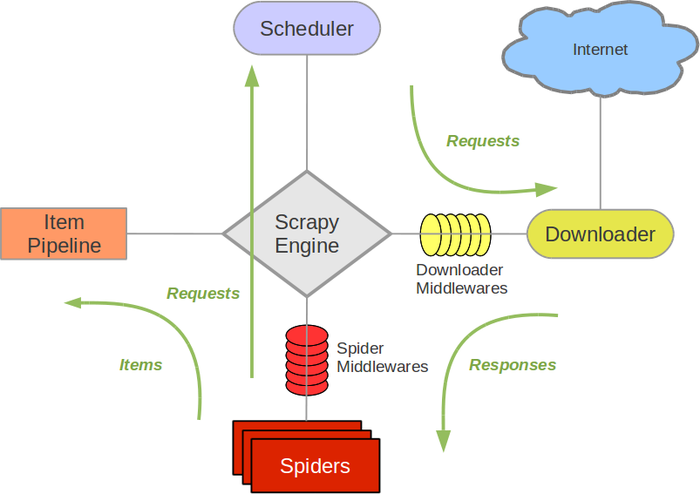
组件
Scrapy Engine
引擎负责控制数据流、当特定动作发生时激活协程。
Scheduler
Scheduler从引擎接受请求(requests),然后把请求入队列(enqueue)。
Downloader
Downloader负责抓取网页,并把它们喂给引擎。
Spiders
Spiders是由scrapy使用者编写的定制的类。负责解析responses并从中提取items以及更多urls
Item Pipeline
负责处理被提取出来的items。常见的处理包括清洗,检测有效性以及存储。
Downloader middlewares
这个中间件是处在engine和downloader中间的特定的钩子,负责处理从engine传出去的请求,以及从downloader传进来的响应。
当有以下需求时使用下载中间件:
-
在request被发送给Downloader之前对其进行处理(亦即在Scrapy把请求发送给网站之前)
-
在response被发送给spider之前想改变它
-
想要给spider发送个新的请求而不是把接收到的response发送给Spider
-
把不带抓回来的网页的response发送给spider
-
安静的扔掉以些requests
Spider middlewares
spider middlewares是在Engine和Spiders中间的特定的钩子,可以处理spider输入(response)和输出(items 和 requests)
当有以下需求时使用爬虫中间件:
- 在回调函数之后对爬虫输出做处理----改变/增加/移除 requwsts或是items
- 对start_requests做后处理
- 处理spider异常
- 根据response内容对某些requests调用errback而不是callback
数据流
Scrapy的数据流是由engine控制的,运行方式如下:
- engine从spider得到第一批urls,并把他们传给scheduler,scheduler将其作为requests入栈
- 引擎跟Scheduler要下一个要爬去的urls
- scheduler把下一个要爬的urls返回给engine,engine把他们发送给Downloader,途经Doader Middlerware
- 一旦页面下载结束,Downloader生成一个Response(带着这个页面)并且把它发送给engine,途经downloader middlewares
- engine接受从downloader发过来的response并且把它发送给spider,途经spider middleware
- spider处理response并且把提取出来的items和新的requests发送给engine,途经spider middlewares
- engine把items发送给item pipelines,把新的requests发送给scheduler
- 返回第一步,继续这个过程,直到没有更多的requests
协程驱动网络
scrapy是用Twisted框架写的。也就是说,它是使用异步非阻塞代码来实现并发的。