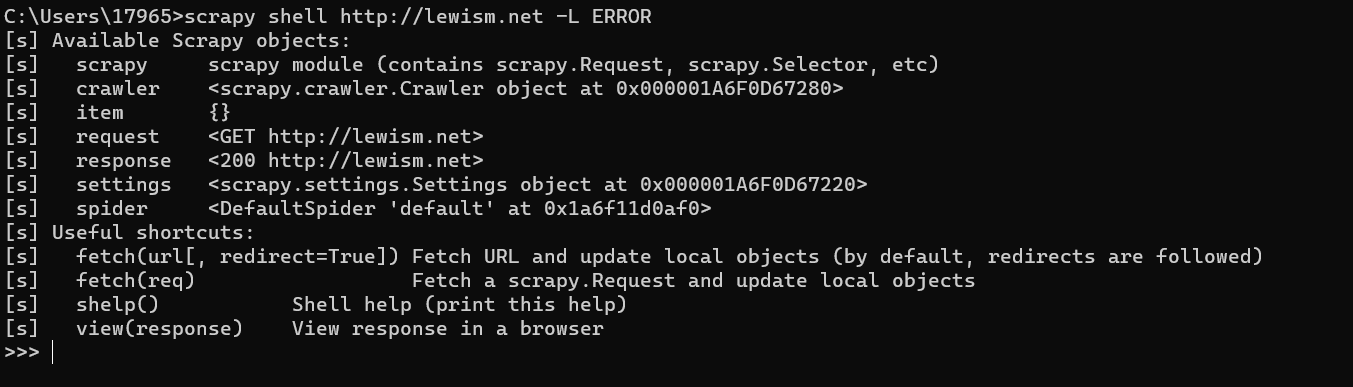
我们在用scrapy写爬虫解析代码的时候经常会遇到比如xpath解析结果和预期不符合这种情况,如果解析的条目多的话一条一条测又很麻烦,又不能每次都跑一遍爬虫来验证结果正不正确,这样不仅效率低,还增加被封的风险,遇到这种情况我们就可以用scrapy shell来帮我们解决这个问题,scrapy自带的shell工具可以让我们实现动态的交互式的开发,例子如下:
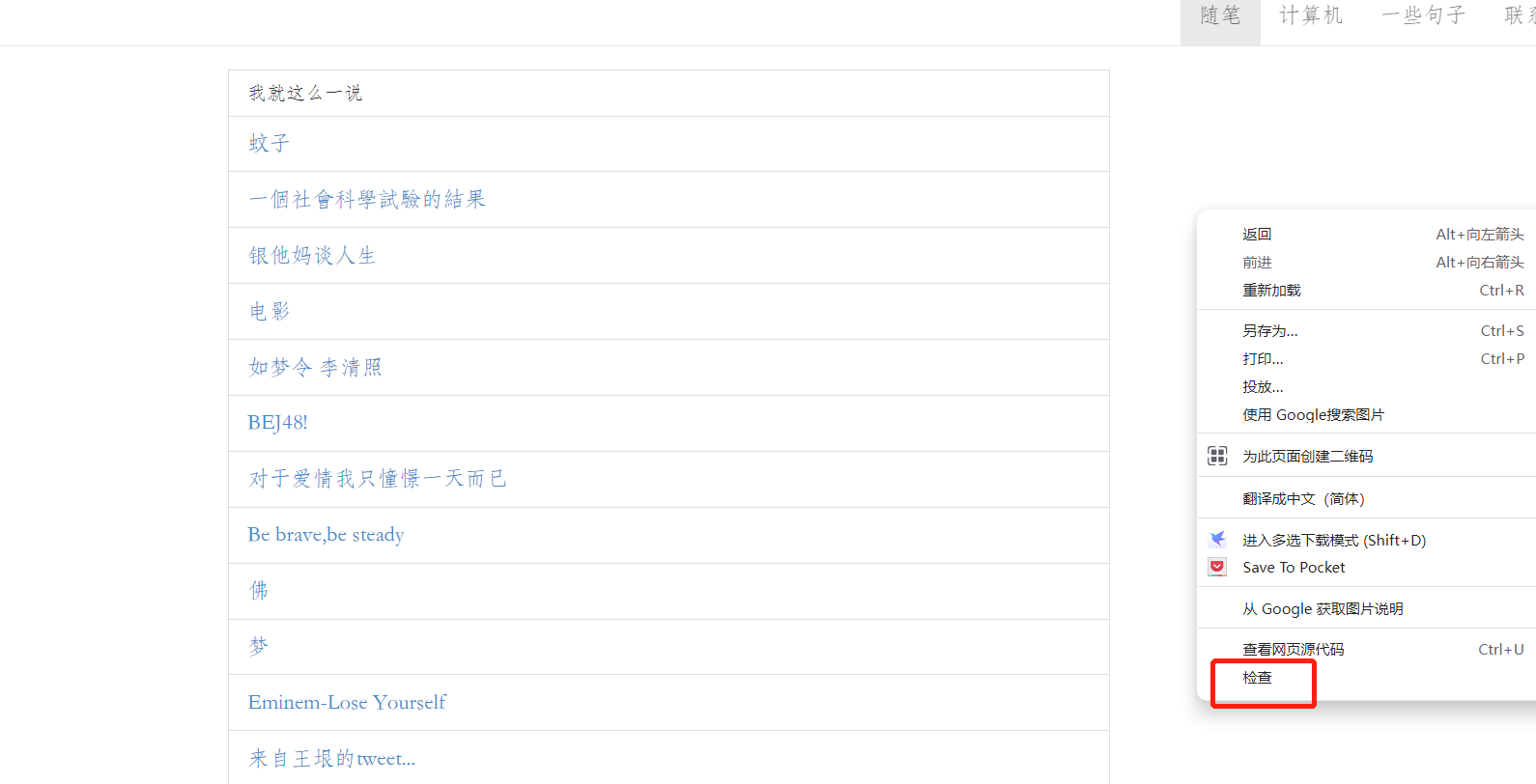
首先有了一个网页,比如我的网站:lewism.net
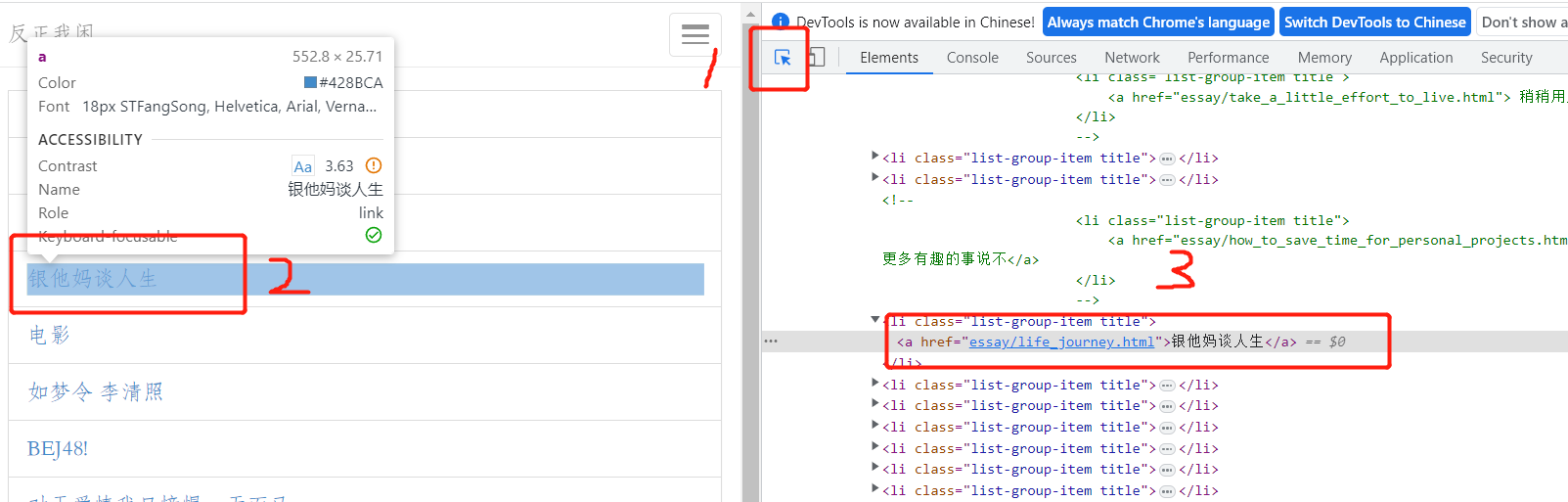
然后用chrome打开,右键,点击检查,打开源码页
接下来比如我们想抓取这些文章的标题,我们在shell里执行命令:
scrapy shell http://lewism.net -L ERROR(此处-L ERROR是设置输出日志等级为error级别,为了让输出更简洁一些,默认为debug级别,也可以在项目的settings文件里修改LOG_LEVEL字段的值来实现,命令行优先级最高,详情请看这里https://blog.csdn.net/jss19940414/article/details/85291157)